
On October 23, 2025, Anthropic and Google announced that Anthropic would expand its use of Google Cloud TPUs to as many as one million chips, bringing well over a gigawatt of computing capacity online in 2026, in a deal worth tens of billions of dollars. Reuters described that capacity as the kind of silicon "traditionally reserved for internal use." Six months later the two companies, joined by Broadcom, signed on for multiple additional gigawatts starting in 2027. Anthropic builds Claude, and Claude is the model that competes most directly with Google's own Gemini. So Google's cloud division spent the better part of a year committing its scarcest strategic asset to the company trying to beat its sister division at the one thing Google has staked its future on.
Hold that next to a second fact. In the same window, Google's own AI researchers were reportedly queuing for TPU time behind paying cloud customers. Sundar Pichai told analysts the company was "supply constrained," with demand across Google's services, DeepMind, and Cloud running ahead of what Google could deliver, and a cloud backlog that had grown to roughly $240 billion. Demis Hassabis, who runs DeepMind, described the constraint plainly in a February interview: "In the end, it comes down to a few suppliers of a few key components." He has also said, with no apparent irony, that Google is "lucky" because it owns its own TPUs -- the same TPUs it was renting out by the gigawatt.
The cleanest account of how this happened comes from Dylan Patel of SemiAnalysis, on Dwarkesh Patel's podcast in March. Patel's read is blunt: "Google screwed up." Anthropic, he says, negotiated for the capacity and locked it in "before Google realized" how much its own Gemini effort was about to need. By his telling, when DeepMind saw the size of the Anthropic allocation, the internal reaction was close to "this is insane, why did we do this," and Google then had to go back to TSMC to justify a sudden increase in capacity -- much of it to cover a customer it had armed before its own demand inflected.
I want to be careful here, because the real story is more interesting than "Google made a dumb mistake."
The right hand, the left hand, and the missing owner
Every large company runs on internal incentives that quietly point in different directions. Google Cloud is measured on revenue, growth, and proof that its custom silicon can win business away from Nvidia. From inside that division, a signed, multi-year, tens-of-billions commitment from a marquee AI lab is not a blunder. It is the best validation the TPU program could ask for, and Thomas Kurian, who runs Google Cloud, said as much, framing the Anthropic deal around the "price-performance and efficiency" Anthropic had seen from TPUs. DeepMind is measured on something completely different: whether Gemini stays at the frontier. From inside that division, every TPU sold to Anthropic is a training run it does not get to do.
Both of those views are correct, which is what makes this a hard problem rather than a careless one. Each division optimized for its own objective, and the sum of two locally rational decisions was a globally strange outcome. The company that owns the best vertically integrated AI stack in the world -- models, cloud, custom chips, networking, data centers -- handed a year of its scarcest output to the competitor best positioned to use it against them. The most useful way to name the failure is not that one hand didn't know what the other was doing. It is that no single person owned the company's compute capacity as a strategic resource. Cloud could rationally book the customer, DeepMind could rationally want the same machines, and Alphabet, with every structural advantage in the industry, still reached a worse answer than a startup a tenth its size with one accountable owner for compute would have reached. If you want to understand a large company, read its incentives, not its press releases -- and Google's incentives were pulling hard in two directions.
I have a small, unglamorous version of this from my own career, and it shaped how I read the Google story.
What I learned at Waymo about being "the same company"
When I was at Waymo, I could never quite answer a simple question: were we Google, or weren't we? On paper we were a separate company under Alphabet. In practice the boundary moved depending on who you were talking to and what you needed from them. When we wanted to use something from the Google Maps team -- data, a piece of the stack -- the conversation was never as simple as "we're all Alphabet, of course." It turned into a negotiation with its own priorities and its own politics, the way it would with an outside vendor. In some real sense, that is what we were.
The same thing ran in reverse. If we wanted to put Google Assistant in the vehicle, whether we could shape the feature roadmap at all -- get our use case prioritized against the thousand other demands on that team -- depended almost entirely on the individual we happened to be connected with. A sympathetic counterpart could make things move. An indifferent one could stall it for months. Some people treated Waymo as "us." Some treated us as a customer. Most were just trying to do the right thing inside their own incentives, and there was no clean rule overhead that said "Alphabet companies coordinate by default."
That kind of ambiguity is manageable when the shared resource is an API integration, a data-sharing workflow, or a slot on a quarterly roadmap. It becomes expensive when the shared resource is a gigawatt of AI accelerators. Coordination across ambitious, separately measured teams is not the default state; it is something you have to build deliberately, against the grain of how the units are scored. The Google-Anthropic situation is that same dynamic, scaled up to the most important input in technology and the highest stakes anyone has played for. It is also why "just consolidate everything" rarely survives contact with a real org. My colleague Sam Tearle has argued that the goal should be to consolidate your data, not your software, precisely because the seams between teams are real, and pretending they aren't is how you get surprised.
The case that Google did the right thing
It is worth steelmanning the other side, because the strongest version of "this was fine" is genuinely strong. Google Cloud exists to sell capacity. Turning away a tens-of-billions customer because a sister division might want the chips later is not obviously the shareholder-friendly choice, especially when that customer validates your silicon against Nvidia in front of every other buyer in the market. The economics are real: Google's TPUs have delivered roughly four times the price-performance of Nvidia's H100 on inference for some workloads, and Midjourney reportedly cut its monthly inference bill from $2.1 million to about $700,000 after moving to them. A reference customer the size of Anthropic turns that claim into a selling point that money cannot otherwise buy.
Google also owns a meaningful slice of Anthropic. It put in around $300 million in early 2023, committed up to $2 billion later that year, and reportedly more than a billion again in 2025, so Anthropic's success is partly Google's hedge against Gemini not winning everything. There is a supply-side argument too. Patel notes that the Anthropic demand shock is part of what sent Google back to TSMC for more capacity in the first place, and a committed external customer can justify supply-chain investment that a soft internal forecast never would. Run all of that together and the Anthropic deal looks less like a fumble and more like a vertically integrated company using an internal market to monetize infrastructure, validate a chip, hedge its model bet, and fund the next turn of the supply chain. This is the make-versus-buy question at planetary scale: Google makes the chip, and then has to decide who else gets to buy it.
There is one cost the steelman has trouble pricing. A cloud P&L can measure the Anthropic contract precisely -- the backlog, the utilization, the margin, the reference value of a marquee logo. It has a much harder time measuring the Gemini experiments that do not run because the quota is gone. Frontier research needs compute for more than serving live traffic; it needs enough to run experiments at a scale where the result actually means something. Hassabis made exactly this point: "you need a lot of chips to be able to experiment on new ideas at a big enough scale that you can actually see if they're going to work." When those experiments queue behind a paying customer, the lost learning never shows up as a line item. It shows up later, as a model that arrives a few months behind. What finally tips this, for me, toward "expensive mistake" is the timing, and the timing is really a story about how compute gets made.
Compute is not a cloud SKU. It is a supply chain.
The reason the Anthropic allocation is hard to undo is that you cannot simply buy more frontier compute the moment you realize you want it. This is the part of Patel's interview that stuck with me, and it is the real subject underneath the org-chart drama: the lead times are measured in years, not weeks.
Start at the bottom of the stack. A single gigawatt of advanced AI capacity, by Patel's math, takes on the order of 55,000 leading-edge 3-nanometer wafers and around twenty extreme-ultraviolet lithography passes per wafer, which works out to roughly two million EUV exposures once you count logic and memory together. The machines that do that exposure, ASML's EUV tools, are the chokepoint, and there is no second supplier. ASML can build about seventy of them a year, heading to eighty next year, and a tool that cost around $150 million is on its way to $400 million by 2028. The fabs that house them, Patel notes, "take two years to build," against a data center that Amazon can stand up in as little as eight months. Standing up the building is the fast part; making the silicon to fill it is what takes years.
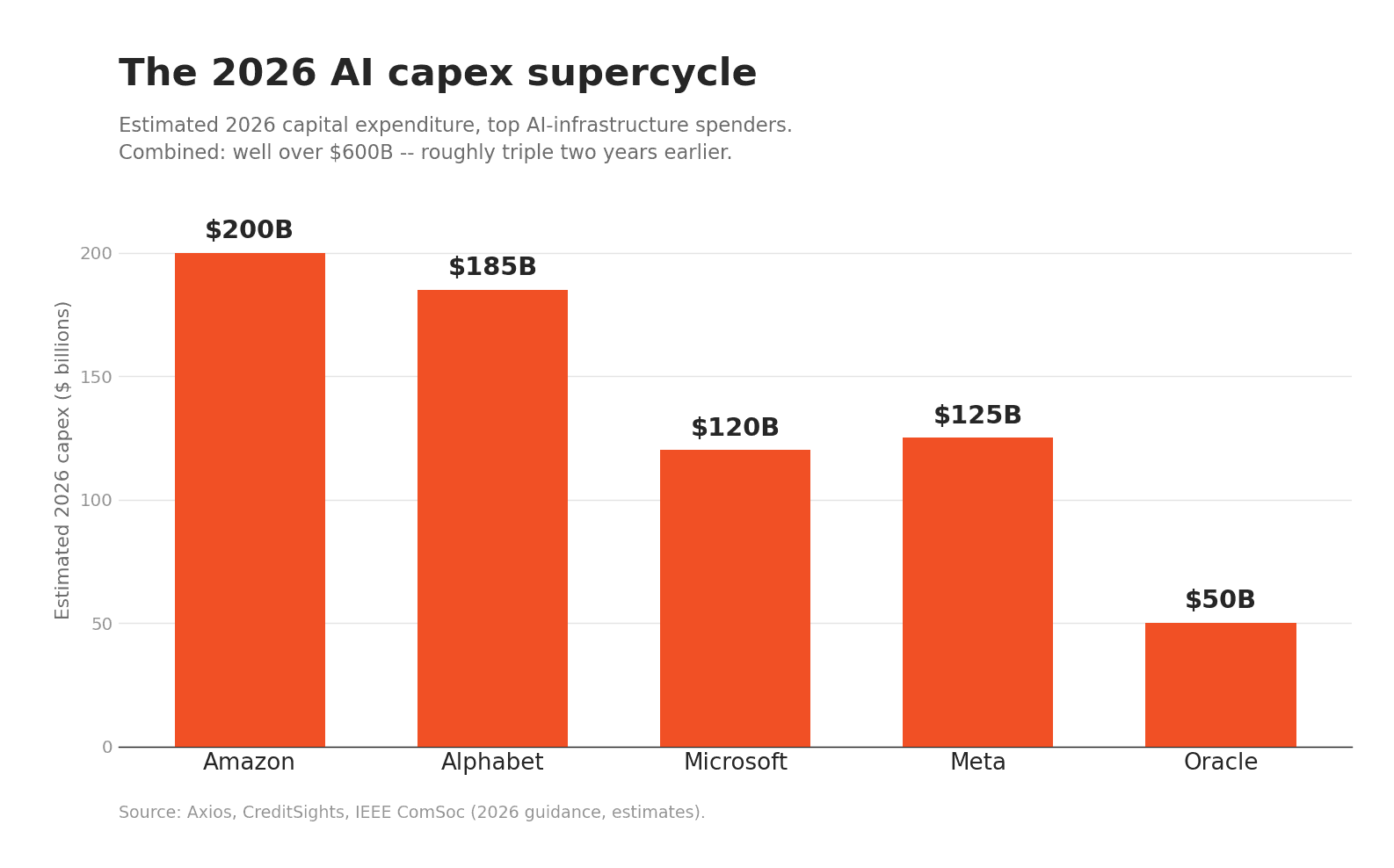
Then there is memory. High-bandwidth memory, the stacks of DRAM that sit next to every accelerator, has become its own binding constraint. By early 2026, all three makers -- SK Hynix, Samsung, and Micron -- had sold out their 2026 HBM capacity, with Micron's contracts booked by January and customers reserving supply years in advance. Samsung and SK Hynix have warned the shortage could run into 2027 and beyond. Patel's framing is that roughly 30% of all Big Tech capital expenditure in 2026, out of a combined figure approaching $600 billion, is going toward memory alone. The bottleneck does not sit still. It rotates between logic, memory, and power -- Patel actually argues power is the most solvable of the three in the US -- but it is always somewhere, and it is always upstream of the thing you want.
What it takes to make frontier compute | The hard number | Why you can't top it up on demand |
|---|---|---|
EUV lithography (ASML) | ~70-80 machines built per year; ~$150M each, rising toward ~$400M by 2028; no second supplier | One company gates the industry's entire output of leading-edge logic |
Leading-edge fabs | "Two years to build" a fab vs. ~8 months for a data center | The building is the fast part; the silicon to fill it is not |
HBM memory | All three makers' 2026 capacity sold out by Q1 2026; shortage warned into 2027+ | Customers reserve years ahead; memory caps how many accelerators ship |
The contract itself | "Non-cancelable, non-returnable... deposits"; hyperscaler capex ~$600B in 2026 | You commit the capital before you know exactly how much you'll need |
Sources: Dylan Patel / SemiAnalysis on the Dwarkesh Patel podcast (March 2026); Tom's Hardware; Axios.
So the way you buy this is nothing like the way you buy cloud. Patel describes the posture directly: "We'll sign non-cancelable, non-returnable. We may even pay deposits." Hyperscaler capital expenditure is expected to clear $600 billion in 2026, roughly triple two years earlier, and Goldman Sachs put the 2025-to-2027 total above $1.15 trillion. OpenAI has reportedly signed deals that could cost more than a trillion dollars to lock in around 26 gigawatts of compute. These are not purchase orders. They are closer to the way an airline orders aircraft a decade out, or an automaker contracts battery cells before the car exists.
None of this is a new shape to anyone who has run a hardware supply chain; it is a new industry discovering an old constraint. Back at Tesla, the components on a twenty-four-month path -- a battery cell line, a large casting tool, an automotive-grade chip in short supply -- were the ones where the capacity decision got made long before the final design debate was settled. You reserved the line, then made the part fit. AI labs now live in that same world, except the bill of materials is EUV passes, HBM stacks, data-center power, and custom networking, and the same shortages run straight into consumer-electronics and automotive BOMs too. It is the dynamic I wrote about in China Time: the company that treats a long-lead input as something to schedule, not something to buy on demand, is the one that still ships.
That is what makes Google's timing expensive rather than merely awkward. When DeepMind's demand inflected, when Gemini took off and Pichai began describing the company as supply constrained, the chips for 2026 were already spoken for. Some of them were spoken for by Anthropic, on contracts Google's own cloud division had signed. You cannot un-sell a non-cancelable gigawatt. The coordination gap would have been a footnote if compute behaved like a commodity you could top up on demand. It behaves like a fab reservation, which is why a missed handoff in 2025 turns into a capability gap in 2026.

Anthropic bought compute like a procurement organization
The mirror image of Google's coordination problem is how deliberately Anthropic has sourced. Anthropic does not depend on a single supplier. It trains and serves Claude across Amazon's Trainium, Google's TPUs, and Nvidia's GPUs, and it has said plainly that the multi-vendor approach is about matching workloads to the right hardware and improving resilience. Its anchor is Amazon's Project Rainier, a cluster of nearly 500,000 Trainium2 chips that came online in under a year, inside a partnership that has Anthropic committing more than $100 billion to AWS over a decade and securing up to five gigawatts of Trainium capacity. On top of that sit the Google TPU gigawatts, Nvidia capacity through clouds like CoreWeave, and strategic investments from Microsoft and Nvidia.
Strip away the zeros and this is textbook sourcing strategy. Anthropic refused to be captured by one vendor, qualified multiple sources for its most critical input, and reserved capacity early, before the crunch made it unbuyable. That is exactly what a good direct materials team does with a sole-source risk on a critical component. The lesson generalizes well past AI labs: when an input is scarce and the lead time is long, the company that reserves early and dual-sources wins, and the company that assumes it can buy on demand finds the capacity gone. Having more than one qualified source does not solve everything on its own -- my colleague Andy Hunt has written about why dual sourcing alone won't save your supply chain when your suppliers all converge on the same sub-tier -- but it is the price of entry, and Anthropic paid it.
The company that refuses to compete with its customers
TSMC manufactures chips for Nvidia, AMD, Apple, Qualcomm, and nearly everyone else, and it has built the most valuable position in the industry, north of 70% of the foundry market, on a single promise: it designs no chips of its own, so it never competes with the customers it builds for. That neutrality is the product it sells, and it is the structural choice Google did not make. Google sells the TPU and runs Gemini, which makes it both the arms dealer and a combatant, and its customers know it.
The contrast points at a question Google had not fully answered when it signed: is TPU capacity a neutral product that Cloud sells to anyone, or a strategic input that Gemini has first claim on? Plenty of companies live in that tension and answer it clearly. Amazon's promise to the market is that a paying customer gets served even when another Amazon business competes with them, which is why Netflix has run on more than 100,000 AWS instances since 2010 while Prime Video competes with it. TSMC answered it the other way, by refusing to have a side at all. Samsung builds the OLED panels in Apple's iPhones while its Galaxy division fights Apple for the same buyers. Each of those companies made the call explicit. The Anthropic deal suggests Google had not, and was letting Cloud and DeepMind each optimize locally while the upstream capacity was already committed. What makes the case sharper than ordinary coopetition is that the thing being sold is not fungible cloud or a commodity display. It is the single scarcest input in the most important race the company is running, on contracts that cannot be unwound for years. The closer the product sits to your core fight, and the longer it takes to make more of it, the more a friendly handoff to a competitor costs you.
Why this rhymes with the factory floor
Strip out the silicon and this is a story most manufacturers will recognize. The two failures in the Google example -- a coordination gap between divisions measured on different things, and a scarce, long-lead input that has to be committed before demand is certain -- are the two failures that quietly decide whether a hardware company launches on time and on cost. Engineering, procurement, and suppliers usually sit in separate tools with separate incentives, so the people choosing the design and the people who have to source it are working from different versions of the truth. By the time procurement is looped in, the expensive decisions are often already locked, which is the sourcing bottleneck that quietly taxes most programs. Closing the gap between the engineering BOM and the sourcing decision is its own discipline, the kind of PLM-and-sourcing marriage most companies never quite arrange.
That second problem is not abstract for anyone building physical products right now. This is the gap LightSource is built to close: connecting engineering, procurement, and suppliers in one system so cost and capacity signals appear while the design can still change, and so a challenger manufacturer can see a sole-source or long-lead exposure on its bill of materials early enough to act on it. The companies we work with are not trying to win on scale. They are trying to win on speed, which means they cannot afford to discover a capacity wall the quarter they hit it. The same logic that took digital twins from Tesla to Waymo applies here: most of the value is in seeing the constraint before it binds.
Google may yet look smart. If TPUs become the credible second source to Nvidia and Google Cloud captures real share of the AI infrastructure market, the Anthropic deal will be remembered as the reference win that made it happen, and the internal grumbling will be a footnote. The same facts that read as dysfunction today could read as strategy in three years. What seems clearly true now is narrower and more durable: compute has become a resource you reserve before you are certain you need it, the way an airline books planes or a carmaker books cells, and a company's internal seams -- the places where one division's incentives stop and another's begin -- now show up directly in what it can and cannot build. The question Google's situation raises, and the one I keep coming back to from my Waymo days, is whether a company that large can ever really coordinate the few decisions that matter most, or whether the org chart wins in the end.
Sources
Anthropic -- Expanding our use of Google Cloud TPUs and services -- the October 23, 2025 announcement: up to one million TPUs, well over a gigawatt online in 2026, tens of billions in value.
CNBC -- Google and Anthropic announce cloud deal worth tens of billions -- deal framing, Thomas Kurian on TPU price-performance, the ~$50B-per-gigawatt context.
Anthropic, Google, and Broadcom -- partnership for multiple gigawatts of compute -- the April 2026 expansion and Anthropic's multi-vendor (Trainium, TPU, Nvidia) strategy.
Tom's Hardware -- Broadcom expands Anthropic deal to ~3.5 GW of Google TPU capacity from 2027 -- scale of the 2027 expansion.
Dwarkesh Patel -- Dylan Patel on the three big bottlenecks to scaling AI compute -- "Google screwed up," the EUV/fab/HBM lead-time math, "non-cancelable, non-returnable."
CRN -- Google CEO on being supply constrained, Gemini 3, and Cloud's $240B backlog -- Pichai on demand across DeepMind and Cloud.
Storyboard18 -- Demis Hassabis warns AI's next bottleneck is memory -- "a few suppliers of a few key components" and the need for chips to experiment at scale.
The Next Web -- Google has sold so much TPU capacity its own researchers are queueing -- reporting on the internal compute squeeze.
About Amazon -- AWS Project Rainier comes online -- the ~500,000-Trainium2 cluster built for Anthropic.
About Amazon -- Amazon invests an additional $5B in Anthropic -- the $100B/10-year AWS commitment and up to 5 GW of Trainium.
VentureBeat -- How Google's TPUs are reshaping the economics of large-scale AI -- TPU vs. H100 price-performance and the Midjourney inference savings.
Tom's Hardware -- Samsung and SK Hynix warn AI memory shortages could last into 2027+ -- HBM sold out, customers reserving years ahead.
Axios -- Hyperscaler spending heads toward ~$610B in 2026 -- the capex supercycle.
AWS -- Netflix case study -- the canonical coopetition example.
Frequently Asked Questions
How many TPUs did Google sell Anthropic, and when?
In October 2025, Google Cloud committed Anthropic access to as many as one million TPUs, bringing well over a gigawatt of capacity online in 2026 in a deal worth tens of billions of dollars. In April 2026, Anthropic, Google, and Broadcom expanded the arrangement to multiple additional gigawatts of next-generation TPU capacity starting in 2027, reported at roughly 3.5 gigawatts. It is the largest external TPU commitment Google has made.
Why would Google sell AI chips to a competitor like Anthropic?
The business case is real: Google Cloud books tens of billions in revenue, proves its TPUs can compete with Nvidia in front of every other buyer, and earns a marquee reference customer. Google also holds an equity stake in Anthropic, so Anthropic's success is partly a hedge against Gemini. The criticism is not that selling was irrational, but that the timing left Google's own DeepMind researchers short of compute when Gemini demand surged.
Is Google's own AI effort short on compute?
Google has publicly described itself as supply constrained. CEO Sundar Pichai pointed to demand across Google's services, DeepMind, and Cloud outrunning supply and a cloud backlog near $240 billion, and DeepMind chief Demis Hassabis has said the constraint comes down to "a few suppliers of a few key components." Reporting suggests Google's own researchers have at times queued for TPU time behind paying customers, though Google has not described it as an internal failure.
What did Dylan Patel say about Google on the Dwarkesh podcast?
On the March 2026 episode, Dylan Patel of SemiAnalysis said flatly that "Google screwed up," arguing Anthropic locked in TPU capacity "before Google realized" how much its own Gemini effort would need. He framed AI scaling around three bottlenecks -- logic, memory, and power -- and emphasized that semiconductor supply chains, not data centers, are the longest-lead constraint.
Why can't AI companies just buy more compute when they need it?
Frontier compute has multi-year lead times. Leading-edge fabs take about two years to build, ASML ships only about 70 to 80 EUV lithography machines a year with no competitor, and all three HBM memory makers had sold out their 2026 capacity by early 2026. Buyers now sign "non-cancelable, non-returnable" contracts and reserve capacity years ahead, the way airlines order aircraft.
What can manufacturers learn from how Anthropic sources compute?
Anthropic multi-sourced its most critical input across Amazon, Google, and Nvidia silicon and reserved capacity early, before shortages made it unbuyable. For any company building physical products, the takeaway is to qualify more than one source for scarce, long-lead components and to commit capacity before demand is certain. Treating critical inputs like a managed supply chain, rather than something you buy on demand, is what separates the companies that ship from the ones that wait.
On October 23, 2025, Anthropic and Google announced that Anthropic would expand its use of Google Cloud TPUs to as many as one million chips, bringing well over a gigawatt of computing capacity online in 2026, in a deal worth tens of billions of dollars. Reuters described that capacity as the kind of silicon "traditionally reserved for internal use." Six months later the two companies, joined by Broadcom, signed on for multiple additional gigawatts starting in 2027. Anthropic builds Claude, and Claude is the model that competes most directly with Google's own Gemini. So Google's cloud division spent the better part of a year committing its scarcest strategic asset to the company trying to beat its sister division at the one thing Google has staked its future on.
Hold that next to a second fact. In the same window, Google's own AI researchers were reportedly queuing for TPU time behind paying cloud customers. Sundar Pichai told analysts the company was "supply constrained," with demand across Google's services, DeepMind, and Cloud running ahead of what Google could deliver, and a cloud backlog that had grown to roughly $240 billion. Demis Hassabis, who runs DeepMind, described the constraint plainly in a February interview: "In the end, it comes down to a few suppliers of a few key components." He has also said, with no apparent irony, that Google is "lucky" because it owns its own TPUs -- the same TPUs it was renting out by the gigawatt.
The cleanest account of how this happened comes from Dylan Patel of SemiAnalysis, on Dwarkesh Patel's podcast in March. Patel's read is blunt: "Google screwed up." Anthropic, he says, negotiated for the capacity and locked it in "before Google realized" how much its own Gemini effort was about to need. By his telling, when DeepMind saw the size of the Anthropic allocation, the internal reaction was close to "this is insane, why did we do this," and Google then had to go back to TSMC to justify a sudden increase in capacity -- much of it to cover a customer it had armed before its own demand inflected.
I want to be careful here, because the real story is more interesting than "Google made a dumb mistake."
The right hand, the left hand, and the missing owner
Every large company runs on internal incentives that quietly point in different directions. Google Cloud is measured on revenue, growth, and proof that its custom silicon can win business away from Nvidia. From inside that division, a signed, multi-year, tens-of-billions commitment from a marquee AI lab is not a blunder. It is the best validation the TPU program could ask for, and Thomas Kurian, who runs Google Cloud, said as much, framing the Anthropic deal around the "price-performance and efficiency" Anthropic had seen from TPUs. DeepMind is measured on something completely different: whether Gemini stays at the frontier. From inside that division, every TPU sold to Anthropic is a training run it does not get to do.
Both of those views are correct, which is what makes this a hard problem rather than a careless one. Each division optimized for its own objective, and the sum of two locally rational decisions was a globally strange outcome. The company that owns the best vertically integrated AI stack in the world -- models, cloud, custom chips, networking, data centers -- handed a year of its scarcest output to the competitor best positioned to use it against them. The most useful way to name the failure is not that one hand didn't know what the other was doing. It is that no single person owned the company's compute capacity as a strategic resource. Cloud could rationally book the customer, DeepMind could rationally want the same machines, and Alphabet, with every structural advantage in the industry, still reached a worse answer than a startup a tenth its size with one accountable owner for compute would have reached. If you want to understand a large company, read its incentives, not its press releases -- and Google's incentives were pulling hard in two directions.
I have a small, unglamorous version of this from my own career, and it shaped how I read the Google story.
What I learned at Waymo about being "the same company"
When I was at Waymo, I could never quite answer a simple question: were we Google, or weren't we? On paper we were a separate company under Alphabet. In practice the boundary moved depending on who you were talking to and what you needed from them. When we wanted to use something from the Google Maps team -- data, a piece of the stack -- the conversation was never as simple as "we're all Alphabet, of course." It turned into a negotiation with its own priorities and its own politics, the way it would with an outside vendor. In some real sense, that is what we were.
The same thing ran in reverse. If we wanted to put Google Assistant in the vehicle, whether we could shape the feature roadmap at all -- get our use case prioritized against the thousand other demands on that team -- depended almost entirely on the individual we happened to be connected with. A sympathetic counterpart could make things move. An indifferent one could stall it for months. Some people treated Waymo as "us." Some treated us as a customer. Most were just trying to do the right thing inside their own incentives, and there was no clean rule overhead that said "Alphabet companies coordinate by default."
That kind of ambiguity is manageable when the shared resource is an API integration, a data-sharing workflow, or a slot on a quarterly roadmap. It becomes expensive when the shared resource is a gigawatt of AI accelerators. Coordination across ambitious, separately measured teams is not the default state; it is something you have to build deliberately, against the grain of how the units are scored. The Google-Anthropic situation is that same dynamic, scaled up to the most important input in technology and the highest stakes anyone has played for. It is also why "just consolidate everything" rarely survives contact with a real org. My colleague Sam Tearle has argued that the goal should be to consolidate your data, not your software, precisely because the seams between teams are real, and pretending they aren't is how you get surprised.
The case that Google did the right thing
It is worth steelmanning the other side, because the strongest version of "this was fine" is genuinely strong. Google Cloud exists to sell capacity. Turning away a tens-of-billions customer because a sister division might want the chips later is not obviously the shareholder-friendly choice, especially when that customer validates your silicon against Nvidia in front of every other buyer in the market. The economics are real: Google's TPUs have delivered roughly four times the price-performance of Nvidia's H100 on inference for some workloads, and Midjourney reportedly cut its monthly inference bill from $2.1 million to about $700,000 after moving to them. A reference customer the size of Anthropic turns that claim into a selling point that money cannot otherwise buy.
Google also owns a meaningful slice of Anthropic. It put in around $300 million in early 2023, committed up to $2 billion later that year, and reportedly more than a billion again in 2025, so Anthropic's success is partly Google's hedge against Gemini not winning everything. There is a supply-side argument too. Patel notes that the Anthropic demand shock is part of what sent Google back to TSMC for more capacity in the first place, and a committed external customer can justify supply-chain investment that a soft internal forecast never would. Run all of that together and the Anthropic deal looks less like a fumble and more like a vertically integrated company using an internal market to monetize infrastructure, validate a chip, hedge its model bet, and fund the next turn of the supply chain. This is the make-versus-buy question at planetary scale: Google makes the chip, and then has to decide who else gets to buy it.
There is one cost the steelman has trouble pricing. A cloud P&L can measure the Anthropic contract precisely -- the backlog, the utilization, the margin, the reference value of a marquee logo. It has a much harder time measuring the Gemini experiments that do not run because the quota is gone. Frontier research needs compute for more than serving live traffic; it needs enough to run experiments at a scale where the result actually means something. Hassabis made exactly this point: "you need a lot of chips to be able to experiment on new ideas at a big enough scale that you can actually see if they're going to work." When those experiments queue behind a paying customer, the lost learning never shows up as a line item. It shows up later, as a model that arrives a few months behind. What finally tips this, for me, toward "expensive mistake" is the timing, and the timing is really a story about how compute gets made.
Compute is not a cloud SKU. It is a supply chain.
The reason the Anthropic allocation is hard to undo is that you cannot simply buy more frontier compute the moment you realize you want it. This is the part of Patel's interview that stuck with me, and it is the real subject underneath the org-chart drama: the lead times are measured in years, not weeks.
Start at the bottom of the stack. A single gigawatt of advanced AI capacity, by Patel's math, takes on the order of 55,000 leading-edge 3-nanometer wafers and around twenty extreme-ultraviolet lithography passes per wafer, which works out to roughly two million EUV exposures once you count logic and memory together. The machines that do that exposure, ASML's EUV tools, are the chokepoint, and there is no second supplier. ASML can build about seventy of them a year, heading to eighty next year, and a tool that cost around $150 million is on its way to $400 million by 2028. The fabs that house them, Patel notes, "take two years to build," against a data center that Amazon can stand up in as little as eight months. Standing up the building is the fast part; making the silicon to fill it is what takes years.
Then there is memory. High-bandwidth memory, the stacks of DRAM that sit next to every accelerator, has become its own binding constraint. By early 2026, all three makers -- SK Hynix, Samsung, and Micron -- had sold out their 2026 HBM capacity, with Micron's contracts booked by January and customers reserving supply years in advance. Samsung and SK Hynix have warned the shortage could run into 2027 and beyond. Patel's framing is that roughly 30% of all Big Tech capital expenditure in 2026, out of a combined figure approaching $600 billion, is going toward memory alone. The bottleneck does not sit still. It rotates between logic, memory, and power -- Patel actually argues power is the most solvable of the three in the US -- but it is always somewhere, and it is always upstream of the thing you want.
What it takes to make frontier compute | The hard number | Why you can't top it up on demand |
|---|---|---|
EUV lithography (ASML) | ~70-80 machines built per year; ~$150M each, rising toward ~$400M by 2028; no second supplier | One company gates the industry's entire output of leading-edge logic |
Leading-edge fabs | "Two years to build" a fab vs. ~8 months for a data center | The building is the fast part; the silicon to fill it is not |
HBM memory | All three makers' 2026 capacity sold out by Q1 2026; shortage warned into 2027+ | Customers reserve years ahead; memory caps how many accelerators ship |
The contract itself | "Non-cancelable, non-returnable... deposits"; hyperscaler capex ~$600B in 2026 | You commit the capital before you know exactly how much you'll need |
Sources: Dylan Patel / SemiAnalysis on the Dwarkesh Patel podcast (March 2026); Tom's Hardware; Axios.
So the way you buy this is nothing like the way you buy cloud. Patel describes the posture directly: "We'll sign non-cancelable, non-returnable. We may even pay deposits." Hyperscaler capital expenditure is expected to clear $600 billion in 2026, roughly triple two years earlier, and Goldman Sachs put the 2025-to-2027 total above $1.15 trillion. OpenAI has reportedly signed deals that could cost more than a trillion dollars to lock in around 26 gigawatts of compute. These are not purchase orders. They are closer to the way an airline orders aircraft a decade out, or an automaker contracts battery cells before the car exists.
None of this is a new shape to anyone who has run a hardware supply chain; it is a new industry discovering an old constraint. Back at Tesla, the components on a twenty-four-month path -- a battery cell line, a large casting tool, an automotive-grade chip in short supply -- were the ones where the capacity decision got made long before the final design debate was settled. You reserved the line, then made the part fit. AI labs now live in that same world, except the bill of materials is EUV passes, HBM stacks, data-center power, and custom networking, and the same shortages run straight into consumer-electronics and automotive BOMs too. It is the dynamic I wrote about in China Time: the company that treats a long-lead input as something to schedule, not something to buy on demand, is the one that still ships.
That is what makes Google's timing expensive rather than merely awkward. When DeepMind's demand inflected, when Gemini took off and Pichai began describing the company as supply constrained, the chips for 2026 were already spoken for. Some of them were spoken for by Anthropic, on contracts Google's own cloud division had signed. You cannot un-sell a non-cancelable gigawatt. The coordination gap would have been a footnote if compute behaved like a commodity you could top up on demand. It behaves like a fab reservation, which is why a missed handoff in 2025 turns into a capability gap in 2026.
Anthropic bought compute like a procurement organization
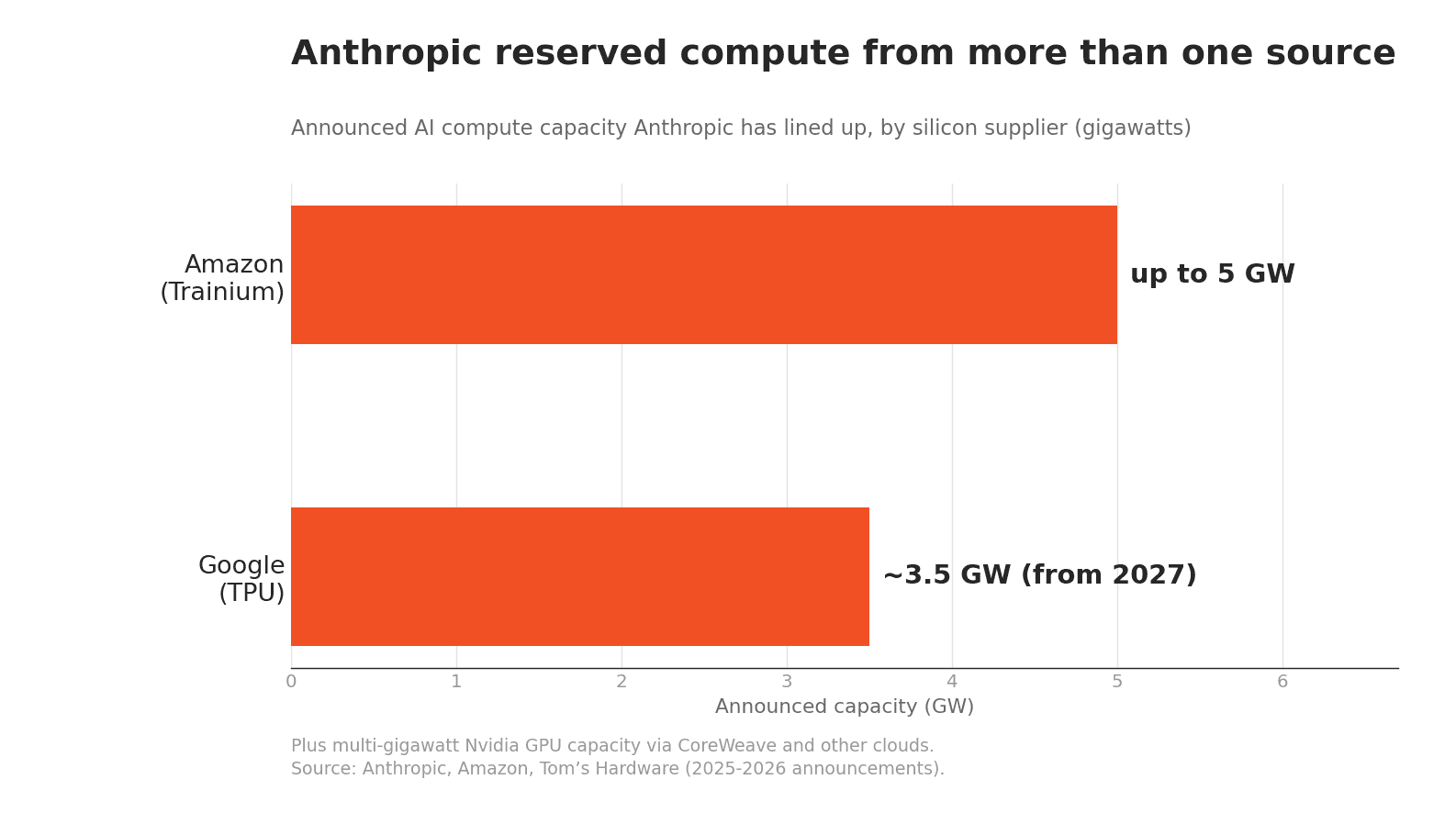
The mirror image of Google's coordination problem is how deliberately Anthropic has sourced. Anthropic does not depend on a single supplier. It trains and serves Claude across Amazon's Trainium, Google's TPUs, and Nvidia's GPUs, and it has said plainly that the multi-vendor approach is about matching workloads to the right hardware and improving resilience. Its anchor is Amazon's Project Rainier, a cluster of nearly 500,000 Trainium2 chips that came online in under a year, inside a partnership that has Anthropic committing more than $100 billion to AWS over a decade and securing up to five gigawatts of Trainium capacity. On top of that sit the Google TPU gigawatts, Nvidia capacity through clouds like CoreWeave, and strategic investments from Microsoft and Nvidia.
Strip away the zeros and this is textbook sourcing strategy. Anthropic refused to be captured by one vendor, qualified multiple sources for its most critical input, and reserved capacity early, before the crunch made it unbuyable. That is exactly what a good direct materials team does with a sole-source risk on a critical component. The lesson generalizes well past AI labs: when an input is scarce and the lead time is long, the company that reserves early and dual-sources wins, and the company that assumes it can buy on demand finds the capacity gone. Having more than one qualified source does not solve everything on its own -- my colleague Andy Hunt has written about why dual sourcing alone won't save your supply chain when your suppliers all converge on the same sub-tier -- but it is the price of entry, and Anthropic paid it.
The company that refuses to compete with its customers
TSMC manufactures chips for Nvidia, AMD, Apple, Qualcomm, and nearly everyone else, and it has built the most valuable position in the industry, north of 70% of the foundry market, on a single promise: it designs no chips of its own, so it never competes with the customers it builds for. That neutrality is the product it sells, and it is the structural choice Google did not make. Google sells the TPU and runs Gemini, which makes it both the arms dealer and a combatant, and its customers know it.
The contrast points at a question Google had not fully answered when it signed: is TPU capacity a neutral product that Cloud sells to anyone, or a strategic input that Gemini has first claim on? Plenty of companies live in that tension and answer it clearly. Amazon's promise to the market is that a paying customer gets served even when another Amazon business competes with them, which is why Netflix has run on more than 100,000 AWS instances since 2010 while Prime Video competes with it. TSMC answered it the other way, by refusing to have a side at all. Samsung builds the OLED panels in Apple's iPhones while its Galaxy division fights Apple for the same buyers. Each of those companies made the call explicit. The Anthropic deal suggests Google had not, and was letting Cloud and DeepMind each optimize locally while the upstream capacity was already committed. What makes the case sharper than ordinary coopetition is that the thing being sold is not fungible cloud or a commodity display. It is the single scarcest input in the most important race the company is running, on contracts that cannot be unwound for years. The closer the product sits to your core fight, and the longer it takes to make more of it, the more a friendly handoff to a competitor costs you.
Why this rhymes with the factory floor
Strip out the silicon and this is a story most manufacturers will recognize. The two failures in the Google example -- a coordination gap between divisions measured on different things, and a scarce, long-lead input that has to be committed before demand is certain -- are the two failures that quietly decide whether a hardware company launches on time and on cost. Engineering, procurement, and suppliers usually sit in separate tools with separate incentives, so the people choosing the design and the people who have to source it are working from different versions of the truth. By the time procurement is looped in, the expensive decisions are often already locked, which is the sourcing bottleneck that quietly taxes most programs. Closing the gap between the engineering BOM and the sourcing decision is its own discipline, the kind of PLM-and-sourcing marriage most companies never quite arrange.
That second problem is not abstract for anyone building physical products right now. This is the gap LightSource is built to close: connecting engineering, procurement, and suppliers in one system so cost and capacity signals appear while the design can still change, and so a challenger manufacturer can see a sole-source or long-lead exposure on its bill of materials early enough to act on it. The companies we work with are not trying to win on scale. They are trying to win on speed, which means they cannot afford to discover a capacity wall the quarter they hit it. The same logic that took digital twins from Tesla to Waymo applies here: most of the value is in seeing the constraint before it binds.
Google may yet look smart. If TPUs become the credible second source to Nvidia and Google Cloud captures real share of the AI infrastructure market, the Anthropic deal will be remembered as the reference win that made it happen, and the internal grumbling will be a footnote. The same facts that read as dysfunction today could read as strategy in three years. What seems clearly true now is narrower and more durable: compute has become a resource you reserve before you are certain you need it, the way an airline books planes or a carmaker books cells, and a company's internal seams -- the places where one division's incentives stop and another's begin -- now show up directly in what it can and cannot build. The question Google's situation raises, and the one I keep coming back to from my Waymo days, is whether a company that large can ever really coordinate the few decisions that matter most, or whether the org chart wins in the end.
Sources
Anthropic -- Expanding our use of Google Cloud TPUs and services -- the October 23, 2025 announcement: up to one million TPUs, well over a gigawatt online in 2026, tens of billions in value.
CNBC -- Google and Anthropic announce cloud deal worth tens of billions -- deal framing, Thomas Kurian on TPU price-performance, the ~$50B-per-gigawatt context.
Anthropic, Google, and Broadcom -- partnership for multiple gigawatts of compute -- the April 2026 expansion and Anthropic's multi-vendor (Trainium, TPU, Nvidia) strategy.
Tom's Hardware -- Broadcom expands Anthropic deal to ~3.5 GW of Google TPU capacity from 2027 -- scale of the 2027 expansion.
Dwarkesh Patel -- Dylan Patel on the three big bottlenecks to scaling AI compute -- "Google screwed up," the EUV/fab/HBM lead-time math, "non-cancelable, non-returnable."
CRN -- Google CEO on being supply constrained, Gemini 3, and Cloud's $240B backlog -- Pichai on demand across DeepMind and Cloud.
Storyboard18 -- Demis Hassabis warns AI's next bottleneck is memory -- "a few suppliers of a few key components" and the need for chips to experiment at scale.
The Next Web -- Google has sold so much TPU capacity its own researchers are queueing -- reporting on the internal compute squeeze.
About Amazon -- AWS Project Rainier comes online -- the ~500,000-Trainium2 cluster built for Anthropic.
About Amazon -- Amazon invests an additional $5B in Anthropic -- the $100B/10-year AWS commitment and up to 5 GW of Trainium.
VentureBeat -- How Google's TPUs are reshaping the economics of large-scale AI -- TPU vs. H100 price-performance and the Midjourney inference savings.
Tom's Hardware -- Samsung and SK Hynix warn AI memory shortages could last into 2027+ -- HBM sold out, customers reserving years ahead.
Axios -- Hyperscaler spending heads toward ~$610B in 2026 -- the capex supercycle.
AWS -- Netflix case study -- the canonical coopetition example.
Frequently Asked Questions
How many TPUs did Google sell Anthropic, and when?
In October 2025, Google Cloud committed Anthropic access to as many as one million TPUs, bringing well over a gigawatt of capacity online in 2026 in a deal worth tens of billions of dollars. In April 2026, Anthropic, Google, and Broadcom expanded the arrangement to multiple additional gigawatts of next-generation TPU capacity starting in 2027, reported at roughly 3.5 gigawatts. It is the largest external TPU commitment Google has made.
Why would Google sell AI chips to a competitor like Anthropic?
The business case is real: Google Cloud books tens of billions in revenue, proves its TPUs can compete with Nvidia in front of every other buyer, and earns a marquee reference customer. Google also holds an equity stake in Anthropic, so Anthropic's success is partly a hedge against Gemini. The criticism is not that selling was irrational, but that the timing left Google's own DeepMind researchers short of compute when Gemini demand surged.
Is Google's own AI effort short on compute?
Google has publicly described itself as supply constrained. CEO Sundar Pichai pointed to demand across Google's services, DeepMind, and Cloud outrunning supply and a cloud backlog near $240 billion, and DeepMind chief Demis Hassabis has said the constraint comes down to "a few suppliers of a few key components." Reporting suggests Google's own researchers have at times queued for TPU time behind paying customers, though Google has not described it as an internal failure.
What did Dylan Patel say about Google on the Dwarkesh podcast?
On the March 2026 episode, Dylan Patel of SemiAnalysis said flatly that "Google screwed up," arguing Anthropic locked in TPU capacity "before Google realized" how much its own Gemini effort would need. He framed AI scaling around three bottlenecks -- logic, memory, and power -- and emphasized that semiconductor supply chains, not data centers, are the longest-lead constraint.
Why can't AI companies just buy more compute when they need it?
Frontier compute has multi-year lead times. Leading-edge fabs take about two years to build, ASML ships only about 70 to 80 EUV lithography machines a year with no competitor, and all three HBM memory makers had sold out their 2026 capacity by early 2026. Buyers now sign "non-cancelable, non-returnable" contracts and reserve capacity years ahead, the way airlines order aircraft.
What can manufacturers learn from how Anthropic sources compute?
Anthropic multi-sourced its most critical input across Amazon, Google, and Nvidia silicon and reserved capacity early, before shortages made it unbuyable. For any company building physical products, the takeaway is to qualify more than one source for scarce, long-lead components and to commit capacity before demand is certain. Treating critical inputs like a managed supply chain, rather than something you buy on demand, is what separates the companies that ship from the ones that wait.
On October 23, 2025, Anthropic and Google announced that Anthropic would expand its use of Google Cloud TPUs to as many as one million chips, bringing well over a gigawatt of computing capacity online in 2026, in a deal worth tens of billions of dollars. Reuters described that capacity as the kind of silicon "traditionally reserved for internal use." Six months later the two companies, joined by Broadcom, signed on for multiple additional gigawatts starting in 2027. Anthropic builds Claude, and Claude is the model that competes most directly with Google's own Gemini. So Google's cloud division spent the better part of a year committing its scarcest strategic asset to the company trying to beat its sister division at the one thing Google has staked its future on.
Hold that next to a second fact. In the same window, Google's own AI researchers were reportedly queuing for TPU time behind paying cloud customers. Sundar Pichai told analysts the company was "supply constrained," with demand across Google's services, DeepMind, and Cloud running ahead of what Google could deliver, and a cloud backlog that had grown to roughly $240 billion. Demis Hassabis, who runs DeepMind, described the constraint plainly in a February interview: "In the end, it comes down to a few suppliers of a few key components." He has also said, with no apparent irony, that Google is "lucky" because it owns its own TPUs -- the same TPUs it was renting out by the gigawatt.
The cleanest account of how this happened comes from Dylan Patel of SemiAnalysis, on Dwarkesh Patel's podcast in March. Patel's read is blunt: "Google screwed up." Anthropic, he says, negotiated for the capacity and locked it in "before Google realized" how much its own Gemini effort was about to need. By his telling, when DeepMind saw the size of the Anthropic allocation, the internal reaction was close to "this is insane, why did we do this," and Google then had to go back to TSMC to justify a sudden increase in capacity -- much of it to cover a customer it had armed before its own demand inflected.
I want to be careful here, because the real story is more interesting than "Google made a dumb mistake."
The right hand, the left hand, and the missing owner
Every large company runs on internal incentives that quietly point in different directions. Google Cloud is measured on revenue, growth, and proof that its custom silicon can win business away from Nvidia. From inside that division, a signed, multi-year, tens-of-billions commitment from a marquee AI lab is not a blunder. It is the best validation the TPU program could ask for, and Thomas Kurian, who runs Google Cloud, said as much, framing the Anthropic deal around the "price-performance and efficiency" Anthropic had seen from TPUs. DeepMind is measured on something completely different: whether Gemini stays at the frontier. From inside that division, every TPU sold to Anthropic is a training run it does not get to do.
Both of those views are correct, which is what makes this a hard problem rather than a careless one. Each division optimized for its own objective, and the sum of two locally rational decisions was a globally strange outcome. The company that owns the best vertically integrated AI stack in the world -- models, cloud, custom chips, networking, data centers -- handed a year of its scarcest output to the competitor best positioned to use it against them. The most useful way to name the failure is not that one hand didn't know what the other was doing. It is that no single person owned the company's compute capacity as a strategic resource. Cloud could rationally book the customer, DeepMind could rationally want the same machines, and Alphabet, with every structural advantage in the industry, still reached a worse answer than a startup a tenth its size with one accountable owner for compute would have reached. If you want to understand a large company, read its incentives, not its press releases -- and Google's incentives were pulling hard in two directions.
I have a small, unglamorous version of this from my own career, and it shaped how I read the Google story.
What I learned at Waymo about being "the same company"
When I was at Waymo, I could never quite answer a simple question: were we Google, or weren't we? On paper we were a separate company under Alphabet. In practice the boundary moved depending on who you were talking to and what you needed from them. When we wanted to use something from the Google Maps team -- data, a piece of the stack -- the conversation was never as simple as "we're all Alphabet, of course." It turned into a negotiation with its own priorities and its own politics, the way it would with an outside vendor. In some real sense, that is what we were.
The same thing ran in reverse. If we wanted to put Google Assistant in the vehicle, whether we could shape the feature roadmap at all -- get our use case prioritized against the thousand other demands on that team -- depended almost entirely on the individual we happened to be connected with. A sympathetic counterpart could make things move. An indifferent one could stall it for months. Some people treated Waymo as "us." Some treated us as a customer. Most were just trying to do the right thing inside their own incentives, and there was no clean rule overhead that said "Alphabet companies coordinate by default."
That kind of ambiguity is manageable when the shared resource is an API integration, a data-sharing workflow, or a slot on a quarterly roadmap. It becomes expensive when the shared resource is a gigawatt of AI accelerators. Coordination across ambitious, separately measured teams is not the default state; it is something you have to build deliberately, against the grain of how the units are scored. The Google-Anthropic situation is that same dynamic, scaled up to the most important input in technology and the highest stakes anyone has played for. It is also why "just consolidate everything" rarely survives contact with a real org. My colleague Sam Tearle has argued that the goal should be to consolidate your data, not your software, precisely because the seams between teams are real, and pretending they aren't is how you get surprised.
The case that Google did the right thing
It is worth steelmanning the other side, because the strongest version of "this was fine" is genuinely strong. Google Cloud exists to sell capacity. Turning away a tens-of-billions customer because a sister division might want the chips later is not obviously the shareholder-friendly choice, especially when that customer validates your silicon against Nvidia in front of every other buyer in the market. The economics are real: Google's TPUs have delivered roughly four times the price-performance of Nvidia's H100 on inference for some workloads, and Midjourney reportedly cut its monthly inference bill from $2.1 million to about $700,000 after moving to them. A reference customer the size of Anthropic turns that claim into a selling point that money cannot otherwise buy.
Google also owns a meaningful slice of Anthropic. It put in around $300 million in early 2023, committed up to $2 billion later that year, and reportedly more than a billion again in 2025, so Anthropic's success is partly Google's hedge against Gemini not winning everything. There is a supply-side argument too. Patel notes that the Anthropic demand shock is part of what sent Google back to TSMC for more capacity in the first place, and a committed external customer can justify supply-chain investment that a soft internal forecast never would. Run all of that together and the Anthropic deal looks less like a fumble and more like a vertically integrated company using an internal market to monetize infrastructure, validate a chip, hedge its model bet, and fund the next turn of the supply chain. This is the make-versus-buy question at planetary scale: Google makes the chip, and then has to decide who else gets to buy it.
There is one cost the steelman has trouble pricing. A cloud P&L can measure the Anthropic contract precisely -- the backlog, the utilization, the margin, the reference value of a marquee logo. It has a much harder time measuring the Gemini experiments that do not run because the quota is gone. Frontier research needs compute for more than serving live traffic; it needs enough to run experiments at a scale where the result actually means something. Hassabis made exactly this point: "you need a lot of chips to be able to experiment on new ideas at a big enough scale that you can actually see if they're going to work." When those experiments queue behind a paying customer, the lost learning never shows up as a line item. It shows up later, as a model that arrives a few months behind. What finally tips this, for me, toward "expensive mistake" is the timing, and the timing is really a story about how compute gets made.
Compute is not a cloud SKU. It is a supply chain.
The reason the Anthropic allocation is hard to undo is that you cannot simply buy more frontier compute the moment you realize you want it. This is the part of Patel's interview that stuck with me, and it is the real subject underneath the org-chart drama: the lead times are measured in years, not weeks.
Start at the bottom of the stack. A single gigawatt of advanced AI capacity, by Patel's math, takes on the order of 55,000 leading-edge 3-nanometer wafers and around twenty extreme-ultraviolet lithography passes per wafer, which works out to roughly two million EUV exposures once you count logic and memory together. The machines that do that exposure, ASML's EUV tools, are the chokepoint, and there is no second supplier. ASML can build about seventy of them a year, heading to eighty next year, and a tool that cost around $150 million is on its way to $400 million by 2028. The fabs that house them, Patel notes, "take two years to build," against a data center that Amazon can stand up in as little as eight months. Standing up the building is the fast part; making the silicon to fill it is what takes years.
Then there is memory. High-bandwidth memory, the stacks of DRAM that sit next to every accelerator, has become its own binding constraint. By early 2026, all three makers -- SK Hynix, Samsung, and Micron -- had sold out their 2026 HBM capacity, with Micron's contracts booked by January and customers reserving supply years in advance. Samsung and SK Hynix have warned the shortage could run into 2027 and beyond. Patel's framing is that roughly 30% of all Big Tech capital expenditure in 2026, out of a combined figure approaching $600 billion, is going toward memory alone. The bottleneck does not sit still. It rotates between logic, memory, and power -- Patel actually argues power is the most solvable of the three in the US -- but it is always somewhere, and it is always upstream of the thing you want.
What it takes to make frontier compute | The hard number | Why you can't top it up on demand |
|---|---|---|
EUV lithography (ASML) | ~70-80 machines built per year; ~$150M each, rising toward ~$400M by 2028; no second supplier | One company gates the industry's entire output of leading-edge logic |
Leading-edge fabs | "Two years to build" a fab vs. ~8 months for a data center | The building is the fast part; the silicon to fill it is not |
HBM memory | All three makers' 2026 capacity sold out by Q1 2026; shortage warned into 2027+ | Customers reserve years ahead; memory caps how many accelerators ship |
The contract itself | "Non-cancelable, non-returnable... deposits"; hyperscaler capex ~$600B in 2026 | You commit the capital before you know exactly how much you'll need |
Sources: Dylan Patel / SemiAnalysis on the Dwarkesh Patel podcast (March 2026); Tom's Hardware; Axios.
So the way you buy this is nothing like the way you buy cloud. Patel describes the posture directly: "We'll sign non-cancelable, non-returnable. We may even pay deposits." Hyperscaler capital expenditure is expected to clear $600 billion in 2026, roughly triple two years earlier, and Goldman Sachs put the 2025-to-2027 total above $1.15 trillion. OpenAI has reportedly signed deals that could cost more than a trillion dollars to lock in around 26 gigawatts of compute. These are not purchase orders. They are closer to the way an airline orders aircraft a decade out, or an automaker contracts battery cells before the car exists.
None of this is a new shape to anyone who has run a hardware supply chain; it is a new industry discovering an old constraint. Back at Tesla, the components on a twenty-four-month path -- a battery cell line, a large casting tool, an automotive-grade chip in short supply -- were the ones where the capacity decision got made long before the final design debate was settled. You reserved the line, then made the part fit. AI labs now live in that same world, except the bill of materials is EUV passes, HBM stacks, data-center power, and custom networking, and the same shortages run straight into consumer-electronics and automotive BOMs too. It is the dynamic I wrote about in China Time: the company that treats a long-lead input as something to schedule, not something to buy on demand, is the one that still ships.
That is what makes Google's timing expensive rather than merely awkward. When DeepMind's demand inflected, when Gemini took off and Pichai began describing the company as supply constrained, the chips for 2026 were already spoken for. Some of them were spoken for by Anthropic, on contracts Google's own cloud division had signed. You cannot un-sell a non-cancelable gigawatt. The coordination gap would have been a footnote if compute behaved like a commodity you could top up on demand. It behaves like a fab reservation, which is why a missed handoff in 2025 turns into a capability gap in 2026.
Anthropic bought compute like a procurement organization
The mirror image of Google's coordination problem is how deliberately Anthropic has sourced. Anthropic does not depend on a single supplier. It trains and serves Claude across Amazon's Trainium, Google's TPUs, and Nvidia's GPUs, and it has said plainly that the multi-vendor approach is about matching workloads to the right hardware and improving resilience. Its anchor is Amazon's Project Rainier, a cluster of nearly 500,000 Trainium2 chips that came online in under a year, inside a partnership that has Anthropic committing more than $100 billion to AWS over a decade and securing up to five gigawatts of Trainium capacity. On top of that sit the Google TPU gigawatts, Nvidia capacity through clouds like CoreWeave, and strategic investments from Microsoft and Nvidia.
Strip away the zeros and this is textbook sourcing strategy. Anthropic refused to be captured by one vendor, qualified multiple sources for its most critical input, and reserved capacity early, before the crunch made it unbuyable. That is exactly what a good direct materials team does with a sole-source risk on a critical component. The lesson generalizes well past AI labs: when an input is scarce and the lead time is long, the company that reserves early and dual-sources wins, and the company that assumes it can buy on demand finds the capacity gone. Having more than one qualified source does not solve everything on its own -- my colleague Andy Hunt has written about why dual sourcing alone won't save your supply chain when your suppliers all converge on the same sub-tier -- but it is the price of entry, and Anthropic paid it.
The company that refuses to compete with its customers
TSMC manufactures chips for Nvidia, AMD, Apple, Qualcomm, and nearly everyone else, and it has built the most valuable position in the industry, north of 70% of the foundry market, on a single promise: it designs no chips of its own, so it never competes with the customers it builds for. That neutrality is the product it sells, and it is the structural choice Google did not make. Google sells the TPU and runs Gemini, which makes it both the arms dealer and a combatant, and its customers know it.
The contrast points at a question Google had not fully answered when it signed: is TPU capacity a neutral product that Cloud sells to anyone, or a strategic input that Gemini has first claim on? Plenty of companies live in that tension and answer it clearly. Amazon's promise to the market is that a paying customer gets served even when another Amazon business competes with them, which is why Netflix has run on more than 100,000 AWS instances since 2010 while Prime Video competes with it. TSMC answered it the other way, by refusing to have a side at all. Samsung builds the OLED panels in Apple's iPhones while its Galaxy division fights Apple for the same buyers. Each of those companies made the call explicit. The Anthropic deal suggests Google had not, and was letting Cloud and DeepMind each optimize locally while the upstream capacity was already committed. What makes the case sharper than ordinary coopetition is that the thing being sold is not fungible cloud or a commodity display. It is the single scarcest input in the most important race the company is running, on contracts that cannot be unwound for years. The closer the product sits to your core fight, and the longer it takes to make more of it, the more a friendly handoff to a competitor costs you.
Why this rhymes with the factory floor
Strip out the silicon and this is a story most manufacturers will recognize. The two failures in the Google example -- a coordination gap between divisions measured on different things, and a scarce, long-lead input that has to be committed before demand is certain -- are the two failures that quietly decide whether a hardware company launches on time and on cost. Engineering, procurement, and suppliers usually sit in separate tools with separate incentives, so the people choosing the design and the people who have to source it are working from different versions of the truth. By the time procurement is looped in, the expensive decisions are often already locked, which is the sourcing bottleneck that quietly taxes most programs. Closing the gap between the engineering BOM and the sourcing decision is its own discipline, the kind of PLM-and-sourcing marriage most companies never quite arrange.
That second problem is not abstract for anyone building physical products right now. This is the gap LightSource is built to close: connecting engineering, procurement, and suppliers in one system so cost and capacity signals appear while the design can still change, and so a challenger manufacturer can see a sole-source or long-lead exposure on its bill of materials early enough to act on it. The companies we work with are not trying to win on scale. They are trying to win on speed, which means they cannot afford to discover a capacity wall the quarter they hit it. The same logic that took digital twins from Tesla to Waymo applies here: most of the value is in seeing the constraint before it binds.
Google may yet look smart. If TPUs become the credible second source to Nvidia and Google Cloud captures real share of the AI infrastructure market, the Anthropic deal will be remembered as the reference win that made it happen, and the internal grumbling will be a footnote. The same facts that read as dysfunction today could read as strategy in three years. What seems clearly true now is narrower and more durable: compute has become a resource you reserve before you are certain you need it, the way an airline books planes or a carmaker books cells, and a company's internal seams -- the places where one division's incentives stop and another's begin -- now show up directly in what it can and cannot build. The question Google's situation raises, and the one I keep coming back to from my Waymo days, is whether a company that large can ever really coordinate the few decisions that matter most, or whether the org chart wins in the end.
Sources
Anthropic -- Expanding our use of Google Cloud TPUs and services -- the October 23, 2025 announcement: up to one million TPUs, well over a gigawatt online in 2026, tens of billions in value.
CNBC -- Google and Anthropic announce cloud deal worth tens of billions -- deal framing, Thomas Kurian on TPU price-performance, the ~$50B-per-gigawatt context.
Anthropic, Google, and Broadcom -- partnership for multiple gigawatts of compute -- the April 2026 expansion and Anthropic's multi-vendor (Trainium, TPU, Nvidia) strategy.
Tom's Hardware -- Broadcom expands Anthropic deal to ~3.5 GW of Google TPU capacity from 2027 -- scale of the 2027 expansion.
Dwarkesh Patel -- Dylan Patel on the three big bottlenecks to scaling AI compute -- "Google screwed up," the EUV/fab/HBM lead-time math, "non-cancelable, non-returnable."
CRN -- Google CEO on being supply constrained, Gemini 3, and Cloud's $240B backlog -- Pichai on demand across DeepMind and Cloud.
Storyboard18 -- Demis Hassabis warns AI's next bottleneck is memory -- "a few suppliers of a few key components" and the need for chips to experiment at scale.
The Next Web -- Google has sold so much TPU capacity its own researchers are queueing -- reporting on the internal compute squeeze.
About Amazon -- AWS Project Rainier comes online -- the ~500,000-Trainium2 cluster built for Anthropic.
About Amazon -- Amazon invests an additional $5B in Anthropic -- the $100B/10-year AWS commitment and up to 5 GW of Trainium.
VentureBeat -- How Google's TPUs are reshaping the economics of large-scale AI -- TPU vs. H100 price-performance and the Midjourney inference savings.
Tom's Hardware -- Samsung and SK Hynix warn AI memory shortages could last into 2027+ -- HBM sold out, customers reserving years ahead.
Axios -- Hyperscaler spending heads toward ~$610B in 2026 -- the capex supercycle.
AWS -- Netflix case study -- the canonical coopetition example.
Frequently Asked Questions
How many TPUs did Google sell Anthropic, and when?
In October 2025, Google Cloud committed Anthropic access to as many as one million TPUs, bringing well over a gigawatt of capacity online in 2026 in a deal worth tens of billions of dollars. In April 2026, Anthropic, Google, and Broadcom expanded the arrangement to multiple additional gigawatts of next-generation TPU capacity starting in 2027, reported at roughly 3.5 gigawatts. It is the largest external TPU commitment Google has made.
Why would Google sell AI chips to a competitor like Anthropic?
The business case is real: Google Cloud books tens of billions in revenue, proves its TPUs can compete with Nvidia in front of every other buyer, and earns a marquee reference customer. Google also holds an equity stake in Anthropic, so Anthropic's success is partly a hedge against Gemini. The criticism is not that selling was irrational, but that the timing left Google's own DeepMind researchers short of compute when Gemini demand surged.
Is Google's own AI effort short on compute?
Google has publicly described itself as supply constrained. CEO Sundar Pichai pointed to demand across Google's services, DeepMind, and Cloud outrunning supply and a cloud backlog near $240 billion, and DeepMind chief Demis Hassabis has said the constraint comes down to "a few suppliers of a few key components." Reporting suggests Google's own researchers have at times queued for TPU time behind paying customers, though Google has not described it as an internal failure.
What did Dylan Patel say about Google on the Dwarkesh podcast?
On the March 2026 episode, Dylan Patel of SemiAnalysis said flatly that "Google screwed up," arguing Anthropic locked in TPU capacity "before Google realized" how much its own Gemini effort would need. He framed AI scaling around three bottlenecks -- logic, memory, and power -- and emphasized that semiconductor supply chains, not data centers, are the longest-lead constraint.
Why can't AI companies just buy more compute when they need it?
Frontier compute has multi-year lead times. Leading-edge fabs take about two years to build, ASML ships only about 70 to 80 EUV lithography machines a year with no competitor, and all three HBM memory makers had sold out their 2026 capacity by early 2026. Buyers now sign "non-cancelable, non-returnable" contracts and reserve capacity years ahead, the way airlines order aircraft.
What can manufacturers learn from how Anthropic sources compute?
Anthropic multi-sourced its most critical input across Amazon, Google, and Nvidia silicon and reserved capacity early, before shortages made it unbuyable. For any company building physical products, the takeaway is to qualify more than one source for scarce, long-lead components and to commit capacity before demand is certain. Treating critical inputs like a managed supply chain, rather than something you buy on demand, is what separates the companies that ship from the ones that wait.
Read more

Source Code Episode 9: Source Code: Shashi Mandapaty, Former Chief Procurement Officer at Johnson & Johnson, on Why One Throne Isn't Enough

Source Code Episode 8: Running on Paper: Rick McDonald, Chief Supply Chain Officer at Clorox, on Why Supplier Trust Is the Real Business Continuity Plan

The IEEPA Ruling Wasn't a Win. Here's What Procurement Leaders Are Missing.
Read more
Source Code Episode 9: Source Code: Shashi Mandapaty, Former Chief Procurement Officer at Johnson & Johnson, on Why One Throne Isn't Enough
Source Code Episode 8: Running on Paper: Rick McDonald, Chief Supply Chain Officer at Clorox, on Why Supplier Trust Is the Real Business Continuity Plan
The IEEPA Ruling Wasn't a Win. Here's What Procurement Leaders Are Missing.
Read more
Source Code Episode 9: Source Code: Shashi Mandapaty, Former Chief Procurement Officer at Johnson & Johnson, on Why One Throne Isn't Enough
Source Code Episode 8: Running on Paper: Rick McDonald, Chief Supply Chain Officer at Clorox, on Why Supplier Trust Is the Real Business Continuity Plan
The IEEPA Ruling Wasn't a Win. Here's What Procurement Leaders Are Missing.
Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Trusted by:
Trusted by:
Trusted by:
*GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and COOL VENDORS is a registered trademark of Gartner, Inc. and/or its affiliates and are used herein with permission. All rights reserved. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.